
A cosa serve l’analisi JavaScript per la SEO
L’analisi JavaScript con Screaming Frog è fondamentale per comprendere come i contenuti generati dinamicamente vengano effettivamente letti dai motori di ricerca.
Nei siti basati su framework come React o Vue.js molti elementi SEO possono non essere visibili nel codice sorgente statico, rendendo indispensabile il rendering JS.
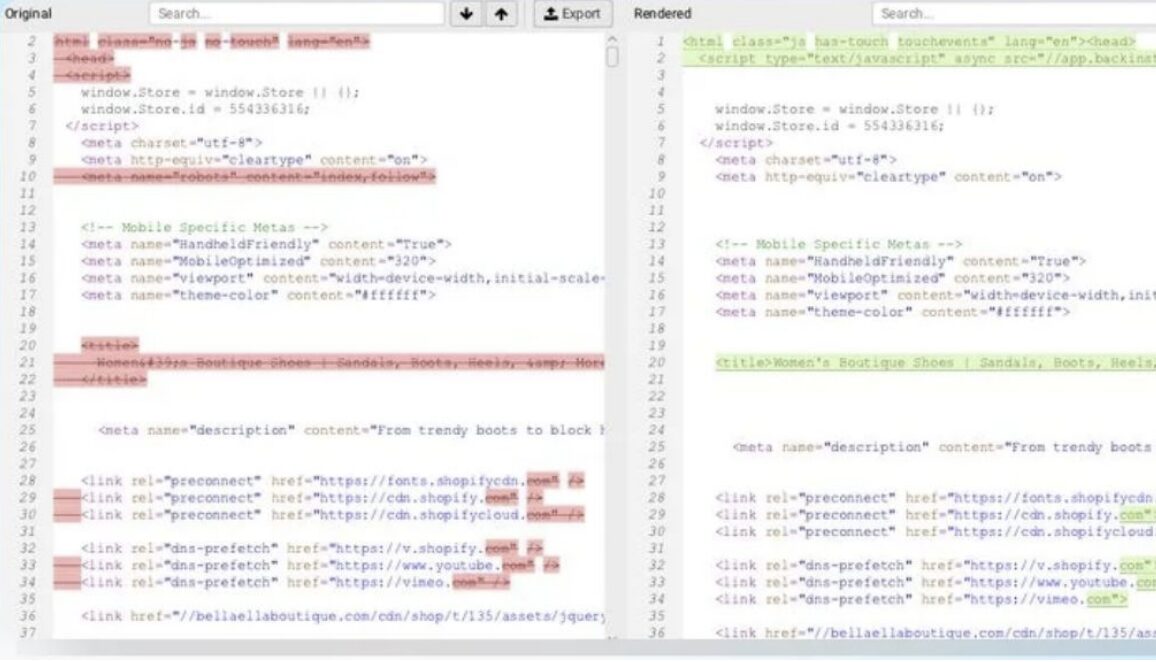
Con la modalità JavaScript attiva, Screaming Frog consente di rilevare differenze tra HTML statico e DOM post-rendering, individuando criticità come titoli mancanti, link non accessibili o contenuti non indicizzati. Questo rende possibile un’ottimizzazione più precisa e mirata.
Infine il tool permette di simulare l’esperienza utente reale, configurando ritardi, interazioni o caricamenti asincroni.
In questo appuntamento con la SEO Tech Academy vediamo come utilizzare Screaming Frog per analisi JS. Se non vuoi perderti i prossimi tutorial, iscriviti al canale YouTube oppure alla newsletter dedicata per riceverli direttamente nella tua casella di posta.
Setup di Screaming Frog per l’analisi JavaScript
- Apri Screaming Frog
- Configura lo Spider per il Rendering: Vai su Configuration > Spider > Rendering e seleziona “JavaScript” nel menù a tendina “Rendering”
- Configura lo Spider per l’Estrazione: Vai su Configuration > Spider > Extraction e assicurati che le opzioni “Store HTML” e “Store Rendered HTML” siano attivate
- Avvia la Scansione: Inserisci l’URL desiderato e avvia il crawl
- Visualizza le Differenze: Nella parte inferiore, vai alla scheda View Source Seleziona la casella “Show Differences” – Usa il menu a tendina per evidenziare le differenze tra contenuto JavaScript e HTML. Le sezioni verdi nella colonna “Rendered” indicano contenuto che richiede JavaScript.
Tipologie di errori e come risolverli
Nella sidebar laterale abbiamo una serie di filtri che ci permetteranno di capire se e come evitare errori di interpretazione da parte del motore di ricerca.
Noindex in HTML Raw
Pagine che contengono un tag noindex nell’HTML grezzo, ma non nell’HTML renderizzato.
Quando Googlebot trova un tag noindex nell’HTML originale, interrompe il processo prima del rendering e dell’esecuzione di JavaScript.
Di conseguenza, rimuovere il noindex tramite JavaScript nel contenuto renderizzato non ha effetto: Googlebot non eseguirà lo script e considera comunque la pagina come da non indicizzare.
PAGINA DA INDICIZZARE → rimuovo il “noindex”
Nofollow in HTML Raw
Pagine che contengono un meta robots “nofollow” nell’HTML grezzo, ma non nell’HTML renderizzato.
Questo implica che tutti i link presenti nell’HTML originale, prima dell’esecuzione del JavaScript, non verranno seguiti dai motori di ricerca.
LINK DA INDICIZZARE → rimuovo il “nofollow”
Canonical Mismatch
Pagine che contengono un link canonico diverso nell’HTML grezzo rispetto a quello nell’HTML renderizzato dopo l’esecuzione del JavaScript.
Google è in grado di elaborare i tag rel=”canonical” anche nell’HTML renderizzato, ma la presenza di link canonici in conflitto tra HTML grezzo e HTML post-rendering può causare risultati imprevisti nell’indicizzazione.
Blocked Resources
Pagine con risorse (come immagini, JavaScript e CSS) bloccate dal rendering a causa di robots.txt o di un errore.
Questo filtro si attiva solo quando il rendering JavaScript è abilitato (le risorse bloccate compariranno come “Blocked by Robots.txt” nella modalità di scansione text only predefinita).
Il problema è che i motori di ricerca potrebbero non riuscire ad accedere a risorse essenziali, compromettendo una corretta interpretazione e visualizzazione della pagina.
Aggiorna il file robots.txt e risolvi eventuali errori per consentire la scansione di tutte le risorse critiche necessarie al rendering dei contenuti del sito.
Le risorse non essenziali (come ad esempio l’embed di Google Maps) possono essere ignorate.
Javascript Links (Content JS)
Pagine che contengono hyperlink presenti solo nell’HTML renderizzato dopo l’esecuzione del JavaScript.
Questi link non sono presenti nell’HTML grezzo e vengono aggiunti dinamicamente, quindi possono essere scoperti dai motori di ricerca solo se il rendering JavaScript è correttamente eseguito.
Anche se Google è in grado di renderizzare le pagine e rilevare i link generati lato client, è consigliabile includere i link importanti direttamente nell’HTML grezzo, lato server, per garantire una scoperta e indicizzazione più affidabile.
Page Title / Meta description / H1 solo in Javascript
Pagine che contengono il titolo della pagina o la Meta Description solo nell’HTML renderizzato dopo l’esecuzione del JavaScript.
Questo significa che i motori di ricerca devono eseguire il rendering della pagina per poterlo visualizzare.
PAGE TITLE/META DESCRIPTION/H1 UPDATE IN JS
Javascript Errors
Pagine con errori JavaScript rilevati nel log della console di Chrome DevTools durante il rendering della pagina.
Sebbene gli errori JavaScript siano comuni e spesso non influenzano significativamente il rendering, possono causare problemi sia nel rendering da parte dei motori di ricerca, compromettendo l’indicizzazione, sia nell’esperienza utente durante l’interazione con la pagina.
Ti è piaciuta questa guida? Se non vuoi perderti i prossimi contenuti, iscriviti al canale YouTube oppure compila il form qui sotto per riceverli direttamente nella tua casella di posta!






