
L’articolo approfondisce il tema dell’indicizzazione degli e-commerce, spiegando come solo le pagine indicizzate dai motori di ricerca possano effettivamente comparire su Google e quindi essere trovate dagli utenti.
- Cos’è l’indicizzazione? Viene spiegato che l’indicizzazione consiste nel far sì che motori di ricerca come Google analizzino e inseriscano le pagine web di un e-commerce nell’indice, rendendole potenzialmente visibili nei risultati di ricerca.
- Come funziona e quali sono le best practice? Analizziamo come i crawler dei motori di ricerca scoprano nuove pagine tramite link interni o sitemap, e l’importanza di creare un file sitemap.xml ben strutturato. Enfatizziamo la selezione delle pagine da indicizzare tramite strumenti come robots.txt, meta tag robots o direttive X-Robots-Tag, lasciando fuori contenuti non rilevanti.
- Controllare l’indicizzazione: Per monitorare quali e quante pagine sono presenti su Google, suggeriamo l’utilizzo dell’operatore site: su Google o degli strumenti di Search Console, utili per verificare rapidamente la presenza e lo stato dei contenuti nell’indice.
- I passaggi fondamentali: Tra i suggerimenti pratici, mettiamo in evidenza come evitare blocchi accidentali tramite robots.txt, controllare che i meta robots consentano l’indicizzazione e che gli URL abbiano il corretto status code. Altri aspetti chiave includono la corretta gestione delle canonical e l’inserimento delle nuove pagine nella sitemap, oltre a garantire backlink interni.
- Accelerare l’indicizzazione: Uno dei metodi efficaci suggeriti per velocizzare la comparsa di nuove pagine su Google è segnalarle manualmente tramite Search Console.
- Le sfide per i grandi e-commerce: Affrontiamo i problemi tipici degli shop online molto ampi, dove la gestione di crawl budget, server e direttive di esclusione può allungare i tempi di indicizzazione.
Cosa significa indicizzare un e-commerce? Come funziona l’indicizzazione sui motori di ricerca e cosa fare se il vostro negozio online non si indicizza
Oggi tratteremo una tematica che in moltissimi casi viene data per scontata e purtroppo sottovalutata da addetti al settore e non, introdurremo il concetto di indicizzazione e spiegheremo a cosa serve e perché è importante per un e-commerce, quali sono le principali attività di routine da svolgere per garantire al proprio sito una corretta indicizzazione e quali sono le problematiche più frequenti e comunemente riscontrate nelle varie piattaforme web. Iniziamo!
Il concetto di indice in poche parole
Attenzione, la lettura di questo articolo è consigliata ad un pubblico “non addetto ai lavori”, per tanto se siete smanettoni, NERD o creature simili potreste annoiarvi a morte : ).
Immaginate di trovarvi in una grande biblioteca perché avete la necessità di cercare un libro. Chiedete all’addetto di turno se è disponibile il titolo x e gentilmente ve lo va a cercare ma torna a mani vuote, vi chiede di tornare qualche giorno dopo perché il libro non è ancora disponibile.
Qualche giorno dopo, ritornate alla biblioteca chiedendo nuovamente il titolo del libro e finalmente l’addetto responsabile ve lo consegna cosi da poterlo iniziare subito a leggere.
Google in linea di massima funziona in maniera molto simile seppur milioni di volte più complessa, infatti l’utente che ha effettuato la ricerca visualizzerà una lista di risultati (libro) pertinenti con la ricerca effettuata (richiesta) grazie all’intervento dei Web Crawler (raccolta libri) che hanno scansionato ed inviato all’indice (archivio biblioteca) il contenuto web individuato.

In parole povere: Google scopre nuove pagine Web eseguendo la scansione del web e le aggiunge al proprio indice, tramite l’utilizzo di software chiamati Spider e ha il compito di mostrarle agli utenti dopo aver eseguito una ricerca specifica.
I risultati vengono elencati grazie ad un complesso algoritmo che ha il compito di classificare i contenuti web.
Come fa lo spider a trovare un contenuto web?
Una volta pubblicato online un contenuto web, perché questo venga indicizzato è necessario che lo spider incaricato ad individuare nuovi contenuti, si accorga della presenza della pagina, per questo motivo è importante che la nuova pagina da indicizzare venga richiamata tramite un collegamento ipertestuale (Backlink) presente in almeno una pagina già presente nell’indice dei motori di ricerca.
Poiché i contenuti dei siti web e degli e-commerce molto spesso sono numerosi e per tanto non facili da individuare, per essere individuati più facilmente viene suggerito di creare una Sitemap, ovvero un file xml contenente tutto l’elenco completo delle pagine web che si ha intenzione di indicizzare. Una sorta di rubrica utile ai Web crawler ad individuare con più facilità tutte le pagine del sito web, in questo modo diventa più semplice trovare i nuovi indirizzi da scansionare.
Tuttavia, non è sempre detto che tuti i contenuti web debbano essere per forza indicizzati, in alcuni casi non è necessario, in altri casi diventa fondamentale non comunicare la presenza di determinati contenuti al motore di ricerca (nei prossimi articoli approfondiremo meglio questa tematica). Quindi come fa a capire lo spider quali sono i contenuti che deve prendere in considerazione e quali invece non deve “leggere”?
Grazie all’utilizzo del file robots.txt, delle intestazioni X-Robots-Tag e del Meta tag Robots.
File Robots.txt

Immaginate di dover visitare una nuova città e di scoprire tutte le vie che la compongono, arrivate alle porte della città e trovate un cartello giallo con scritto che via Rossi, via Bianchi e via Verdi non sono percorribili in auto.
Il file robots.txt funziona in maniera molto simile. È un foglio di testo che contiene un elenco di direttive utili al web crawler per capire quali contenuti può leggere e quali invece non è autorizzato a leggere.
È la prima risorsa che consulta prima di effettuare un tentativo di scansione di un contenuto web, pertanto se avete dei contenuti importanti da comunicare siate sicuri che essi non vengano bloccati dal file Robots.txt!
Meta Tag Robots

Torniamo all’esempio precedente, state visitando la nuova città e sapete che non potete accedere in nessuna delle 3 vie sopra menzionate. Ad un tratto vi imbattete in una quarta via, non menzionata nel cartello collocato alle porte della città, la quale presenta un segnale di divieto di accesso. Voi non potete entrare in quella via perché il cartello ve lo impone.
Il Meta tag Robots funziona proprio in questo modo e serve per comunicare agli spider che quel contenuto non deve essere indicizzato.
A differenza del segnale stradale, visibile all’utente, questa direttiva non si può vedere se non consultando il codice sorgente della pagina. Questo perché al visitatore poco interessa la sua presenza, a differenza del motore di ricerca che invece riesce a “vederla”.
X-Robots-Tag
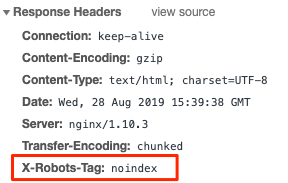
La comunicazione tra client e server avviene tramite lo scambio di pacchetti di informazioni. Un esempio di comunicazione di questo tipo è la visita di una pagina web. Il browser utilizzato invia una richiesta al web server per ottenere informazioni o dati da esso, come ad esempio una pagina HTML.
Durante la fase di richiesta e risposta vengono scambiate non solo le informazioni relative al contenuto presente nella pagina HTML ma anche delle informazioni aggiuntive, grazie alle intestazioni http, come ad esempio l’indirizzo consultato, il peso della pagina, il codice di risposta, la data in cui è stata effettuata la richiesta eccetera.
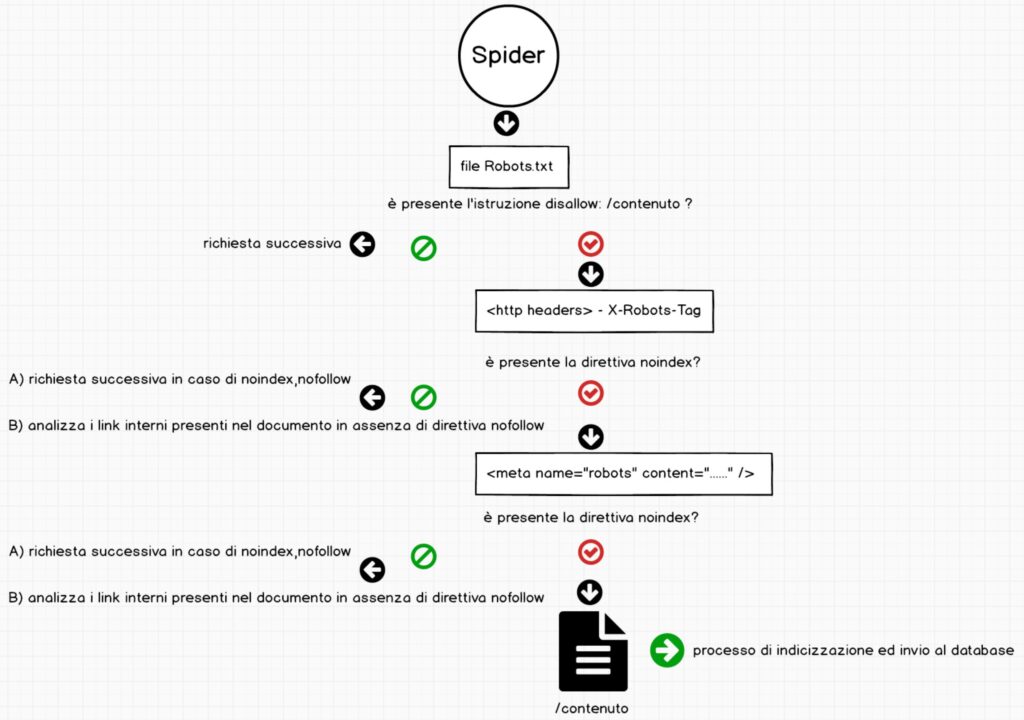
Tra le intestazioni http troviamo anche X-Robot-tag, il suo funzionamento è identico al Meta Robots aggiunto nella sezione <head> del sito web ma rispetto a quest’ultimo ha maggior valenza e meno valenza del file robots.txt da un punto di vista gerarchico. Nell’immagine che segue proviamo a spiegare meglio il concetto.
Come verificare l’indicizzazione su Google
Operatore site:
Andate su Google e utilizzate questa query:
site:iltuosito.com

Il motore di ricerca restituirà il numero approssimativo di tutte le pagine del vostro sito presenti attualmente nel suo indice.
Per verificare lo stato di indicizzazione di un URL specifico basterà ripetere la stessa operazione:
site:iltuosito.com/nome-della-pagina-specifica
Se la pagina non è presente nell’indice non si vedrà nessun risultato
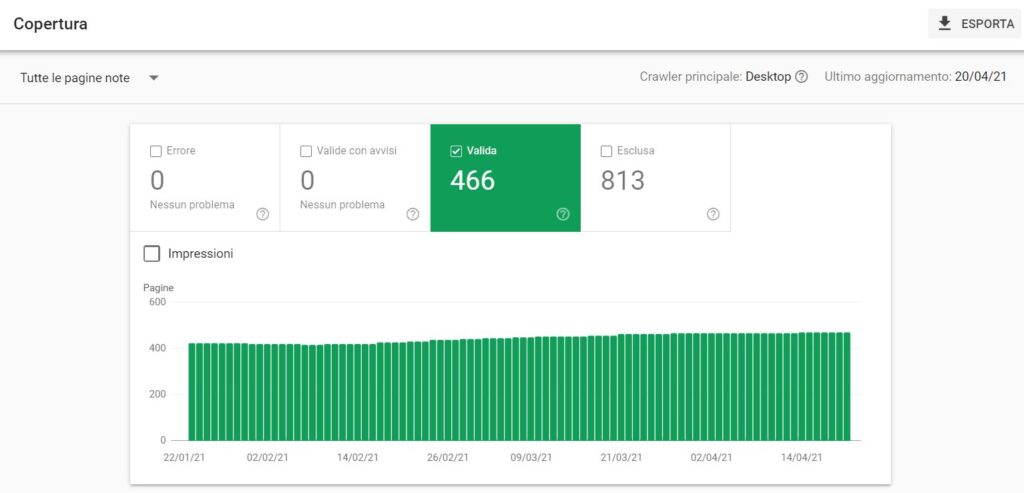
Stato copertura indice (Google Search Console)
Accedere allo strumento Search Console di Google e visitare la sezione “Copertura” (Google Search Console > Indice > Copertura)

e visualizzare il numero di pagine “valide”
Come aiutare gli spider ad indicizzare più velocemente le pagine web?
Per indicizzare un sito web è richiesto del tempo, maggiore sarà il numero di pagine che lo spider dovrà consultare, maggiore sarà il tempo impiegato per completare tutta l’indicizzazione.
Su e-commerce di larga scala, il processo di indicizzazione può durare anche settimane se non un paio di mesi. Inoltre bisogna tenere in considerazione altri fattori importanti come ad esempio il crawl budget, le web performance e le prestazioni del server, tematiche che affronteremo in un articolo dedicato.
Nel caso in cui l’e-commerce sia già presente nell’indice dei motori di ricerca ed abbiamo la necessità di comunicare l’ingresso di una nuova sezione del catalogo, sarà sufficiente accertarso che le nuove pagine siano linkate da pagine già presenti nell’indice ma soprattutto che siano presenti nella sitemap.xml.
Per velocizzare ulteriormente il processo di indicizzazione è possibile inviare i nuovi URL tramite lo strumento Search Console di Google.
Come indicizzare una nuova pagina web con Google Search Console
Se vi siete accorti che le vostre nuove pagine non sono presenti nell’indice dei motori di ricerca, seguite questi step(oppure fatevi aiutare dal vostro team SEO):
- assicuratevi che le pagine non siano bloccate da direttive presenti nel file robots.txt;
- verificate l’eventuale presenza e valore del parametro X-Robots-Tag nelle intestazioni HTTP;
- assicuratevi che la pagina risponda correttamente (Status code 200);
- verificate il meta robots presente all’interno del codice HTML delle pagine;
- assicuratevi che le nuove pagine vengano richiamate correttamente dalla Sitemap;
- assicuratevi che le nuove pagine vengano richiamate da pagine già presenti (ed autorevoli) nell’indice di Google;
- assicuratevi che le direttive Canonical siano settate correttamente.
Infine, accedete alla Search Console di Google ed incollate nella barra in alto il vostro URL che volete inserire nell’indice, premete invio e poi premete il tasto “RICHIESTA DI INDICIZZAZIONE”


In conclusione
Molte volte, i contenuti di un sito web non vengono indicizzati per le problematiche elencate poco fa, seguendo questi accorgimenti ed avendo molta pazienza avrete un’elevata percentuale di successo di risoluzione del problema. Ad ogni modo, se non siete addetti ai lavori affidatevi sempre al vostro team SEO di riferimento!






