
In questo articolo parliamo nel dettaglio del file robots.txt, un elemento tecnico chiave per gestire la scansione e l’indicizzazione dei siti web, con un focus particolare sulla sua importanza per la SEO avanzata.
- Che cos’è il robots.txt: Spieghiamo in modo chiaro a cosa serve il file robots.txt e perché risulta fondamentale per orientare i motori di ricerca, risparmiare risorse (gestione del crawl budget) e proteggere aree sensibili del sito.
- Sintassi e comandi: Analizziamo i principali comandi del file, come User-agent, Disallow, Allow, l’uso di caratteri speciali come l’asterisco (*) per i pattern e il dollaro ($) per la fine stringa, mostrando vari esempi pratici per strutturare un file efficace.
- Best practice e casi concreti: Forniamo best practice su come scrivere il file robots.txt per siti eCommerce o corporate, con esempi reali, attenzione a sintassi, gestione dei disallow selettivi e l’importanza di testing continuo con strumenti come Google Search Console e Screaming Frog.
- Errori da evitare: Dedichiamo ampio spazio agli errori più comuni che vediamo in consulenza, come una gestione errata del crawl budget, direttive duplicate, errori con i jolly, problemi di maiuscole/minuscole, rischi per la sicurezza e svantaggi nell’indicizzazione di risorse strategiche (ad esempio CSS o JS).
- Case study reale: Raccontiamo l’intervento su un caso concreto, dove un errore nel robots.txt stava bloccando l’indicizzazione di pagine importanti, risolto grazie a un’analisi approfondita durante un audit tecnico SEO.
- Gestione delle modifiche: Offriamo suggerimenti su versionamento, testing e monitoraggio delle modifiche, con attenzione particolare agli strumenti utili per prevenire errori e alle procedure per pubblicare in sicurezza nuove versioni del file.
Cos’è il file Robots.txt
Il file Robots.txt è un piccolo ma essenziale file di testo che indica ai motori di ricerca quali pagine del sito possono essere scansionate e quali devono essere escluse.
Ottimizzare questo file significa migliorare la gestione del crawl budget e prevenire problemi come la scansione di contenuti duplicati o non rilevanti, preservando così l’efficacia del posizionamento SEO.
Quindi per il sito www.esempio.com, il file robots.txt si troverà all’indirizzo www.esempio.com/robots.txt.
Sebbene non esista uno standard ufficiale per il file Robots.txt, molti professionisti del settore si affidano a Robotstxt.org come riferimento principale. Tuttavia, è essenziale notare che questo sito riflette lo standard del 1994, che rappresenta solo una minima parte di ciò che è possibile fare con il Robots.txt. Oltre alle direttive base, oggi è possibile implementare funzionalità avanzate come l’uso del carattere jolly, l’integrazione delle sitemap e la direttiva Allow. I principali motori di ricerca hanno adottato e supportano queste funzioni.
Dunque il file robots.txt svolge un ruolo cruciale nella gestione delle richieste dei crawler verso specifiche pagine o risorse di un sito web. La sua funzione primaria è quindi quella di regolare l’accesso e dirigere il traffico dei bot, piuttosto che nascondere risorse specifiche. Per impedire esplicitamente ai motori di ricerca di indicizzare una determinata pagina, è consigliabile invece utilizzare il tag “noindex”.
Tuttavia, è fondamentale sottolineare che le pagine elencate nel file robots.txt possono comunque apparire nei risultati di ricerca, presentando uno snippet con la dicitura “Nessuna informazione disponibile per questa pagina”. Infatti se una pagina bloccata tramite robots.txt riceve link da siti esterni, esiste la possibilità che i bot la indicizzino comunque.
È anche essenziale ricordare che non tutti i motori di ricerca potrebbero rispettare le direttive del file robots.txt. Pertanto, è imperativo progettare un file robots.txt che sia adeguato alle necessità specifiche del sito, garantendo al contempo una navigazione ottimizzata per i bot.
Come funziona il Robots.txt
Se sei già a conoscenza delle direttive del file Robots.txt ma hai timore di commettere errori puoi saltare direttamente alla sezione dedicata agli Errori comuni da evitare. Se invece sei nuovo all’argomento, continua a leggere.
Il file
Il file robots.txt viene creato utilizzando un semplice editor di testo normale. Come riportato in precedenza, deve risiedere nella directory principale del sito e deve essere chiamato “robots.txt”. Non è possibile utilizzare il file in una sottodirectory.
Il Robots.txt segue una sintassi precisa che deve essere rispettata per evitare errori o problemi di indicizzazione. La sintassi prevede due elementi principali: User-agent e Direttive.
User-agent è il nome del crawler del motore di ricerca a cui ci si rivolge. Ad esempio, Googlebot è il crawler di Google, Bingbot è quello di Bing e così via. Si può usare il carattere * per indicare tutti i crawler. La direttiva è l’istruzione che si dà al crawler su quali pagine o file possono o non possono essere scansionati. Le direttive più comuni sono Allow e Disallow, che servono rispettivamente a consentire o impedire l’indicizzazione. Si può usare il carattere / per indicare tutta la directory principale del sito.
Un esempio di Robots.txt è il seguente:
User-agent: *
Disallow: /admin/
Disallow: /carrello/
Allow: /blog/
Questo significa che si impedisce a tutti i crawler di scansionare le pagine o i file che si trovano nelle directory /admin/ e /carrello/, ma si consente la scansione delle pagine o dei file che si trovano nella directory /blog/.
User-Agent
In un file robots.txt, la direttiva user-agent viene utilizzata per specificare quale crawler deve rispettare un determinato insieme di regole. Questa direttiva può essere un carattere jolly per specificare che le regole si applicano a tutti i crawler:
User-agent: *
Oppure può essere il nome di uno specifico crawler:
User-agent: Googlebot
Direttiva Disallow
Dopo la riga user-agent è possibile inserire una o più direttive disallow:
User-agent: *
Disallow: /pagina-da-bloccare
L’esempio precedente bloccherà tutti gli URL il cui percorso inizia con “/pagina-da-bloccare”, ad esempio:
http://esempio.com/pagina-da-bloccare
http://esempio.com/pagina-da-bloccare?parametro=1
http://esempio.com/pagina-da-bloccare/pagina-destinazione
http://esempio.com/pagina-da-bloccare-come-usare-file-robotstxt
Non bloccherà alcun URL il cui percorso non inizia con “/pagina-da-bloccare”. Il seguente URL ad esempio non verrà bloccato:
http://esempio.com/subdirectory/pagina-da-bloccare
Direttiva Allow
È possibile utilizzare questa direttiva per specificare eccezioni a una regola di non autorizzazione se ad esempio, si dispone di una sottodirectory che si desidera bloccare ma si desidera eseguire la scansione di una pagina all’interno di tale sottodirectory:
User-agent: *
Allow: /pagina-da-bloccare/pagina-da-non-bloccare
Disallow: /pagina-da-bloccare/
Questo esempio bloccherà i seguenti URL:
http://esempio.com/pagina-da-bloccare/
http://esempio.com/pagina-da-bloccare/pagina-esempio-1
http://esempio.com/pagina-da-bloccare/pagina-esempio-2
http://esempio.com/pagina-da-bloccare/?parametro=1
Ma non bloccherà nessuno dei seguenti:
http://esempio.com/pagina-da-bloccare/pagina-da-non-bloccare
http://esempio.com/pagina-da-bloccare/pagina-da-non-bloccare-test
http://esempio.com/pagina-da-bloccare/pagina-da-non-bloccare/pagina-test
http://esempio.com/pagina-da-bloccare/pagina-da-non-bloccare?parametro=1
Carattere Jolly
L’operatore jolly è supportato anche da tutti i principali motori di ricerca. Ciò consente di bloccare le pagine quando una parte del percorso è sconosciuta o variabile. Per esempio:
Disallow: /cartella/*/pagina
L’asterisco * significa “corrisponde a qualsiasi testo”. Url di esempio bloccati:
http://esempio.com/cartella/test1/pagina
http://esempio.com/cartella/test2/pagina
http://esempio.com/cartella/test3/pagina
Quanto sopra bloccherà anche i seguenti URL:
http://esempio.com/cartella/test1/test2/test3/levels/pagina
http://esempio.com/cartella/test1/search?q=/pagina
http://esempio.com/cartella/test1/pagina-di-esempio
Operatore $ di fine stringa
Un’altra istruzione utile è l’operatore di fine stringa:
Disallow: /pagina-da-bloccare$
Il simbolo $ indica che l’URL deve terminare in quel punto. Questa direttiva bloccherà solo il seguente URL:
http://esempio.com/pagina-da-bloccare
File Robot tutto chiuso
Se un sito è privato o in fase di sviluppo, si potrebbe voler bloccare la scansione dell’intero sito. Per farlo è necessario utilizzare un disallow seguito da una barra:
User-agent: *
Disallow: /
File Robot tutto aperto
Per consentire invece la scansione dell’intero sito, si può utilizzare un disallow vuoto:
User-agent: *
Disallow:
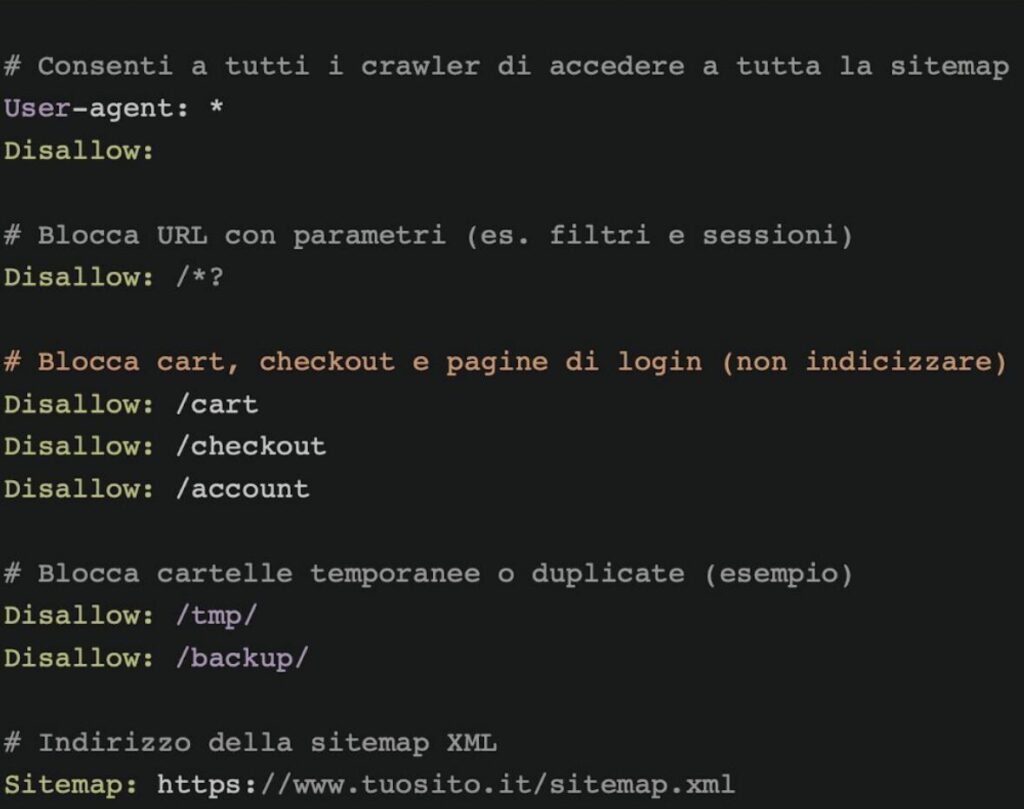
10 Errori comuni da evitare sul file Robots
Ecco dieci errori comuni da evitare quando si lavora con il file Robots.txt:
1. Non ripetere le direttive generali dell’user-agent nei blocchi specifici dell’user-agent
I bot dei motori di ricerca aderiranno al blocco user-agent più vicino corrispondente in un file robots.txt e gli altri blocchi user-agent verranno ignorati. In questo esempio, Googlebot seguirebbe solo la singola regola specificamente indicata per Googlebot e ignorerebbe il resto.
User-agent: *
Disallow: /pagina1
Disallow: /pagina2
Disallow: /pagina3
User-agent: Googlebot
Disallow: /pagina4
In questa situazione è importante ripetere le direttive generali dell’user-agent che si applicano anche a bot più specifici quando si aggiungono regole anche per loro:
User-agent: *
Disallow: /pagina1
Disallow: /pagina2
Disallow: /pagina3
User-agent: Googlebot
Disallow: /pagina1
Disallow: /pagina2
Disallow: /pagina3
Disallow: /pagina4
2. Dimenticare che la regola corrispondente più lunga vince
Quando si utilizzano le regole allow, si applicheranno solo se il numero di caratteri nella regola corrispondente è più lungo. Quando esistono diversi livelli di dettaglio in robots.txt, Google infatti seguirà la regola di corrispondenza più specifica. Ad esempio:
Disallow: /pagina1
Allow: /pagina
Nell’esempio sopra, esempio.com/pagina1 sarà disallow, poiché ci sono più caratteri corrispondenti nella regola disallow. Tuttavia, si può ingannare questa specifica utilizzando il carattere jolly (*) per rendere la regola allow più estesa.
Disallow: /pagina1
Allow: /pagina*
3. Aggiungere il carattere jolly alla fine delle regole
Il carattere jolly * non deve essere sempre aggiunto alla fine delle regole nel file robots.txt, a meno che non lo si utilizzi in modo che sia la regola corrispondente più lunga, poiché sono corrispondenze ampie alla fine della regola per impostazione predefinita.
Disallow: /pagina1*
4. Non utilizzare regole separate per ogni sottodominio
I file Robots.txt dovrebbero evitare di includere regole che coprono diversi sottodomini. Ogni sottodominio richiede il proprio file robots.txt separato. Ad esempio, dovrebbero esistere file robots.txt separati per www.esempio.com e sottodominio.esempio.com.
5. Inclusione di URL relativi della direttiva sitemap
In un file robots.txt, le sitemap non possono essere indicate utilizzando un percorso relativo ma devono essere assolute. Ad esempio, /sitemap.xml non sarebbe rispettato.
6. Ignorare caratteri maiuscoli e minuscoli
I percorsi fanno distinzione tra lettere maiuscole e minuscole. Ad esempio la seguente riga di comando:
Disallow: /pagina1
Non bloccherà “/Pagina1” o “/PAGINA1”. Se si desidera impedire la scansione di tutti i percorsi è necessario inserire una riga disallow separata per ciascuno di loro:
Disallow: /pagina1
Disallow: /Pagina1
Disallow: /PAGINA1
7. Dimenticare la riga dello user-agent
La riga relativa allo user-agent è fondamentale per il file robots.txt, il quale deve contenere questa istruzione prima delle altre. Ad esempio se il file robots fosse impostato in questo modo:
Disallow: /pagina1
Disallow: /pagina2
Disallow: /pagina3
In realtà non verrà bloccato nulla, poiché non è presente alcuna riga relativa allo user-agent. Un esempio di file corretto è il seguente:
User-agent: *
Disallow: /pagina1
Disallow: /pagina2
Disallow: /pagina3
8. Bloccare l’indicizzazione di risorse essenziali per il rendering delle pagine
Immagini, CSS o JavaScript sono risorse utili ai fini della SEO. Questo può compromettere la qualità visiva del sito e influire negativamente sull’esperienza degli utenti e sui segnali di ranking.
9. Usare il Robots.txt per nascondere i contenuti duplicati o di bassa qualità
Il Robots.txt non impedisce ai crawler di seguire i link presenti nelle pagine bloccate, quindi non è efficace per evitare le penalizzazioni dei motori di ricerca. Invece si dovrebbero usare altri metodi, come il tag canonical, il tag noindex o il redirect 301.
10. Usare il Robots.txt per proteggere le informazioni sensibili o private
Il Robots.txt non garantisce la sicurezza dei dati in quanto è facilmente accessibile da chiunque. Inoltre i motori di ricerca non sono obbligati a rispettare le direttive del Robots.txt e quindi potrebbero indicizzare comunque le pagine o i file che si tenta di bloccare.
Case Study: un errore comune su un file robots.txt di un nostro cliente
Durante l’Audit SEO svolto per un nostro cliente è emerso un errore abbastanza comune sul file robots.txt. Il file si presentava con un’istruzione di Disallow vuoto per Googlebot e successivamente erano indicati User-agent generico (*) e alcune regole di Disallow:
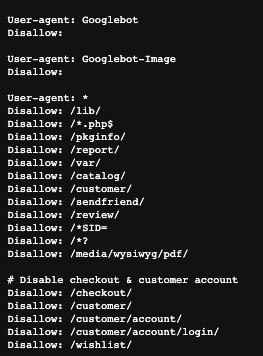
La prima istruzione di Disallow vuoto però consentiva al bot di Google di ignorare tutte le altre istruzioni, rendendo dunque tutto scansionabile, come ad esempio le pagine di checkout sul sito ecommerce del cliente. Ecco un test del file eseguito con Screaming Frog:
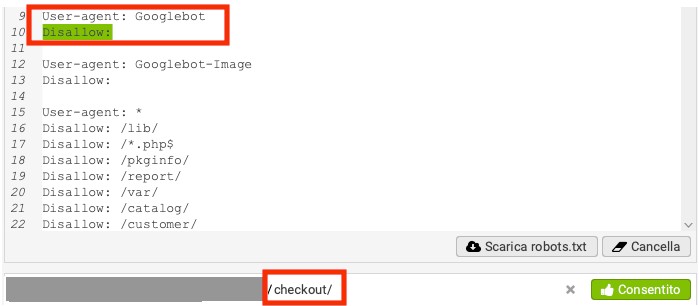
E’ stato dunque necessario apportare modifiche al file robots.txt per risolvere questa problematica e ottimizzare il crawl-budget per Googlebot.
Gestione delle modifiche al Robots.txt
Scrivere e modificare un file robots.txt può creare confusione anche agli esperti SEO. Basta infatti un solo carattere errato per avere un impatto importante sulle prestazioni o addirittura deindicizzare l’intero sito. Se diverse persone lavorano sullo stesso sito, non è insolito che vengano effettuate modifiche senza preavviso o che venga caricata per sbaglio una vecchia versione. In questo caso Google Search Console è un ottimo strumento per risalire ad un possibile errore, ma cosa si può fare per proteggere correttamente il sito? Ecco alcuni suggerimenti per gestire le modifiche al Robots.txt:
- Utilizzare un sistema di controllo versione
Un sistema di controllo versione consente di tenere traccia delle modifiche apportate al file Robots.txt nel tempo e di ripristinare facilmente una versione precedente se necessario. Inoltre, si può utilizzare un sistema di controllo versione per collaborare con altri membri del team e revisionare le modifiche prima che vengano implementate. - Utilizzare strumenti per testare il file robots
Utilizzare il Robots Testing Tool di Google Search Console per verificare le direttive disallow e il loro corretto funzionamento. In alternativa si può utilizzare lo strumento del “Robots personalizzato” su Screaming Frog. - Utilizzare un ambiente di test
Prima di apportare modifiche al file Robots.txt in produzione, è sempre una buona norma testarle in un ambiente di test. Ciò consente di verificare che le modifiche non abbiano effetti indesiderati prima che vengano implementate. - Monitorare le modifiche
Monitorare le modifiche apportate al file Robots.txt può aiutare a identificare rapidamente eventuali problemi. Si può utilizzare strumenti come Google Search Console per monitorare le modifiche e ricevere avvisi se vengono rilevati problemi.
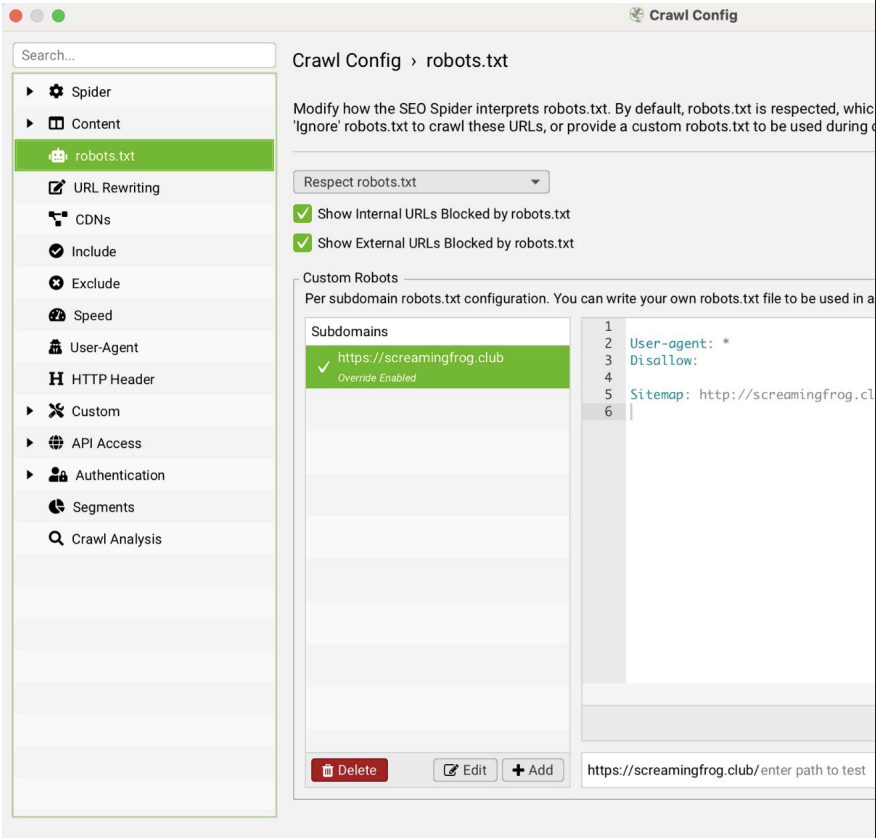
Controllare il file robots.txt con Screaming Frog
Su Screaming Frog, nelle impostazioni del file robots.txt, puoi configurare queste opzioni chiave:
- Respect robots.txt: Il crawler rispetta le direttive di blocco del file robots.txt presente sul sito.
- Ignore robots.txt: Il crawler ignora completamente le regole robots.txt e scansiona tutto.
- Ignore robots.txt but report status: Il crawler ignora i blocchi ma mostra nei report quali URL sarebbero stati bloccati. Inoltre, puoi scegliere se visualizzare o nascondere nelle tabelle le URL interne ed esterne bloccate da robots.txt, e puoi fare test più avanzati caricando un robots.txt personalizzato da usare solo durante il crawl.
Queste opzioni sono accessibili in: Configuration > Robots.txt
Gestire il robots.txt di un eCommerce Shopify
I “Remote Products” (Prodotti Remoti) sono una funzionalità relativamente nuova che consente ai merchant Shopify di visualizzare e vendere prodotti che non sono fisicamente gestiti o di proprietà dello store principale, ma che provengono da una fonte esterna o “remota” (come un altro store Shopify, un fornitore di dropshipping o una rete di marketplace).
Quando un cliente aggiunge un Prodotto Remoto al carrello, le disposizioni di spedizione (e talvolta gli sconti) sono gestite separatamente dallo store di origine, non dallo store che lo visualizza.

Shopify genera automaticamente un file robots.txt per ogni store. Storicamente, e ancora oggi, questo file è parzialmente bloccato per l’utente, sebbene sia disponibile l’editing tramite robots.txt.liquid.
La funzione principale di questo file automatico è prevenire la scansione e l’indicizzazione di contenuto duplicato o non necessario, come:
- Pagine del carrello (/cart) e del checkout.
- Pagine di ricerca interne (/search).
- URL delle collezioni con parametri di ordinamento o filtraggio (es. collections/?sort_by=…), che genererebbero molteplici URL per la stessa pagina.
Quando i Prodotti Remoti vengono visualizzati sullo storefront, possono generare nuove tipologie di URL temporanee, duplicate o a basso valore per il motore di ricerca (Googlebot).
La problematica tecnica è che il robots.txt predefinito di Shopify potrebbe non essere aggiornato per bloccare specificamente le stringhe di query o i percorsi URL unici generati da questa nuova funzionalità di Prodotti Remoti.
Queste direttive utilizzano caratteri jolly (*) e un’espressione per abbinare un identificatore univoco (simile a un UUID) seguito dalla stringa -remote.
Lo scopo è bloccare la scansione (crawling) di tutti gli URL che corrispondono a queste strutture e che sono generate dal sistema Shopify per i Prodotti Remoti.
La risposta è che il file robots.txt non supporta lo standard completo delle espressioni regolari (regex), ma i principali motori di ricerca (in particolare Google) supportano un set limitato di caratteri jolly (wildcards) che estende le regole.
I “character class” come [a-f0-9] e le funzioni più avanzate delle regex (come +, ?, parentesi (), pipe |) NON fanno parte dello standard riconosciuto da Google e Bing per il robots.txt.
Il punto chiave è che la sintassi [a-f0-9] nel robots.txt di Shopify non è un comando di regex, ma è semplicemente una parte fissa e letterale di un pattern creato per abbinarsi a una stringa che il sistema garantisce che sia presente nell’URL secondo una logica di caratteri esadecimali che compongono l’UUID (Identificatore Univoco Universale).
Disallow: /*-remote$
Domande frequenti sul file robots.txt
A cosa serve il file robots.txt?
Il file robots. txt serve per comunicare ai crawler quali pagine di un sito web possono essere scansionate.
Come funziona il file robots.txt?
Il file robots.txt è costituito da uno o più blocchi di direttive, ognuna delle quali inizia con una riga riguardante il tipo di bot, determinato attraverso il suo user-agent e prosegue con le istruzioni che consentono di bloccare o consentire l’accesso a specifiche aree del sito, pagine o URL.
Dove si trova il file robots.txt?
Il file robots. txt si trova nella directory principale del sito. Quindi per il sito www.esempio.com, il file robots.txt si trova all’indirizzo www.esempio.com/robots.txt.
Come evitare che Google scansioni una pagina?
Se si desidera impedire a Google di scansionare totalmente o parzialmente un sito, si può utilizzare il cosiddetto robots.txt per indicare al crawler quali contenuti scansionare e quali escludere. Per non indicizzare specifici URL si può utilizzare invece il Meta Tag Robots.
Quali motori di ricerca rispettano il file robots.txt?
I principali motori di ricerca elencati di seguito rispettano il file robots.txt: Google, Bing, Yahoo, DuckDuckGo, Yandex, Baidu.
Qual è la dimensione massima di un file robots.txt?
Google attualmente supporta per la dimensione del file robots.txt un limite massimo di 500 KB. I contenuti che superano questa dimensione massima vengono ignorati.
Il crawl delay è ancora valido?
Molti motori di ricerca utilizzano crawler che riconoscono ancora la direttiva “Crawl-delay”. Questa direttiva stabilisce un intervallo di tempo, espresso in secondi, che i bot e i crawler devono rispettare prima di inviare la successiva richiesta al server web. La finalità primaria del parametro “crawl-delay” è prevenire un eccessivo afflusso di richieste al server, specialmente in presenza di siti web di grandi dimensioni. Per i siti di dimensioni ridotte questa direttiva risulta generalmente superflua. Googlebot non tiene conto della direttiva “crawl-delay”: per regolare la frequenza di crawling di Googlebot è necessario accedere alla Google Search Console e utilizzare la funzione “crawl-rate”.
Conclusione
In sintesi, il file Robots.txt è uno strumento potente che può aiutare a gestire l’indicizzazione di un sito. Tuttavia è importante utilizzarlo con attenzione per evitare errori comuni che potrebbero avere un impatto negativo sulle prestazioni. Seguendo i suggerimenti e le linee guida fornite in questo articolo, sarai in grado di gestire correttamente il file Robots.txt del tuo sito e garantire che i motori di ricerca possano scansionare le pagine che desideri.






